PL: Misja Gynvaela PL012 czyli zip && crc32 cracking
Wreszcie…⌗
… znalazłem trochę czasu, żeby nadgonić zaległości w misjach. Obecny tryb pracy niestety nie pozwala mi na zbyt częste i treściwe postowanie (…tak obiecałem… pamiętam). Ale udało mi się dorwać poprzednią misję z polskiego streamu. Moim zdaniem jest na tyle ciekawa, że warto ją przybliżyć. Zacznijmy, jak zwykle, od początku.
MISJA 012 goo.gl/kBeZex DIFFICULTY: ██████░░░░ [6/10]
┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅
Podczas przeszukiwania zdobytych dysków znaleźliśmy plik ZIP z hasłem. Ponieważ
nie znamy hasła - a mamy powody przypuszczać, że jest bardzo dobrej jakości i nie
do zgadnięcia czy złamania - to postanowiliśmy zwrócić się do Ciebie z prośbą o
pomoc:
goo.gl/zYoYiq
Powodzenia!
--
Odzyskaną wiadomość umieść w komentarzu pod tym video :)
Linki do kodu/wpisów na blogu/etc z opisem rozwiązania są również mile widziane!
P.S. Rozwiązanie zadania przedstawię na jednym z vlogów w okolicy dwóch tygodni.

Próba wypakowania kończy się:
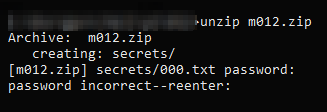
Pomimo wyraźnego odradzenia przez Gyna prób zgadywania hasła, nie byłbym sobą, gdybym jednak nie odpalił crackera:
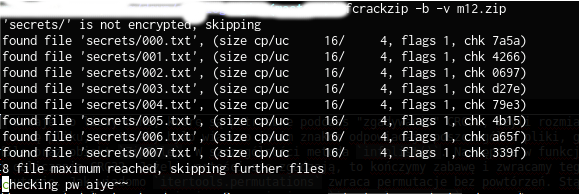
W tym czasie zacząłem szukać alternatywnego sposobu poznania zawartości 20 plików o rozszerzeniu .txt. W tym celu otworzyłem sobie archiwum za pomocą hexedytora. Co zwróciło moją uwagę, to rozmiary zawartości. Pliki przed zaszyfrowaniem, mają rozmiar maksymalnie 4 bajtów. Zaszyfrowane dane mają aż 16 bajtów. Po długim przeszukiwaniu sieci oraz lektury specyfikacji nie udało mi się namierzyć jakiejś podatności w implementacji samego szyfrowania AESem. W związku z tym, że zadanie było ocenione na 6 pkt. na 10 możliwych, to chyba zacząłem szukać za daleko. Te 4 bajty nie dawały mi spokoju. Aż do chwili gdy po raz kolejny patrząc w hexedytor zauważyłem:
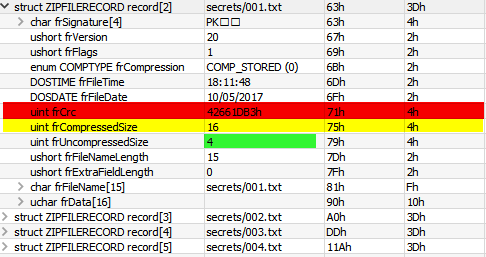
CRC32! Ciekawe czy jest liczone przed czy po szyfrowaniu. Okazuje się, że suma kontrola wyliczana jest przed szyfrowaniem i kompresowaniem danych (co w sumie jest oczywiste i intuicyjne). Dodatkowo crc32 dla 4 bajtów nie ma kolizji, stąd możemy próbować odwrócić proces obliczania checksumy lub skorzystać z brutalnej mocy obliczeniowej CPU (dla ambitnych GPU) i znaleźć te znaki, dla których suma kontrolna się zgadza. Oczywiście najpierw wybrałem najprostsze rozwiązanie, czyli bruteforce. W tym celu skorzystałem z następującego skryptu (yay, Python ma bardzo dobry support zip files):
#!/usr/bin/env python
import zipfile
import zlib
import itertools
import string
def crack(fn):
for i in itertools.product(list(string.printable), repeat=fn['size']):
j = ''.join(i)
if (zlib.crc32(bytes(j, 'utf-8')) & 0xffffffff) == fn['crc32']:
print("file: {}\t{}".format(fn['name'], j))
return j
print("file: {}\t\t crc32:{}".format(fn['name'], fn['crc32']))
return ""
def main():
z = zipfile.ZipFile('m012.zip')
fs = []
for i in z.infolist():
fs.append({'name': i.filename, 'crc32': i.CRC, 'size': i.file_size})
flag = ''
#pool = Pool(processes=4)
#for fn in pool.map(crack, fs):
# print(fn)
for fn in fs:
flag += crack(fn)
print("And the flag is: {}".format(flag))
if __name__ == '__main__':
main()
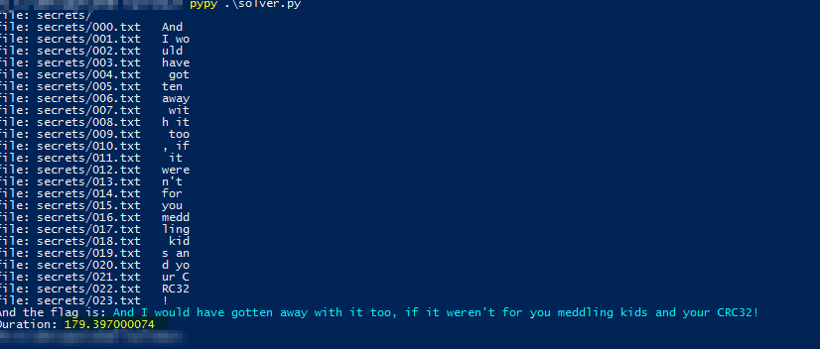
Kod jest mega prosty. W funkcji main dodaje do listy dane, które są potrzebne podczas “zgadywania” CRC32, czyli rozmiar (liczba bajtów) nieskompresowanego pliku oraz sama suma kontrolna. Dodatkowo zapamiętuje nazwę pliku, po to aby było wiadomo jakim znakom odpowiadają poszczególne pliki, gdyby kolejność miała znaczenie. Poznanie szczegółów archiwum zip umożliwia biblioteka zipfile oraz obiekt ZipFile. W szczególności metoda infolist(). Następnie w funkcji crack, każdy ciąg o długości równej rozmiarowi dokumentu txt, jest poddawany operacji obliczania CRC32. Jeżeli wartości się zgadzają, to kończymy zabawę i zwracamy tego stringa. Początkowo popełniłem błąd i zamiast iloczynu karteziańskiego wstawiłem permutację. Jak wiadomo itertools.permutations zwraca permutacje bez powtórzeń. Stąd słowa takie jak *too* lub *away* nie pojawiły się w rozwiązaniu i końcowa flaga wyglądała trochę dziwnie. Po zamianie na itertools.product otrzymałem poprawne (chyba, w końcu wszystkie znaki są printowalne i nawet mają sens) rozwiązanie:
file: secrets/
file: secrets/000.txt And
file: secrets/001.txt I wo
file: secrets/002.txt uld
file: secrets/003.txt have
file: secrets/004.txt got
file: secrets/005.txt ten
file: secrets/006.txt away
file: secrets/007.txt wit
file: secrets/008.txt h it
file: secrets/009.txt too
file: secrets/010.txt , if
file: secrets/011.txt it
file: secrets/012.txt were
file: secrets/013.txt n't
file: secrets/014.txt for
file: secrets/015.txt you
file: secrets/016.txt medd
file: secrets/017.txt ling
file: secrets/018.txt kid
file: secrets/019.txt s an
file: secrets/020.txt d yo
file: secrets/021.txt ur C
file: secrets/022.txt RC32
file: secrets/023.txt !
And the flag is: And I would have gotten away with it too, if it weren't for you meddling kids and your CRC32!
I to by było na tyle. Oczekiwanie na rozwiązanie trwało ponad 8 minut. Na CTFie taki czas pewnie by mnie satysfakcjonował. W końcu działa. Ale nie jest to optymalny sposób na poradzenie sobie z problemem. Poniżej przedstawiam moje próby przyspieszenia odzyskiwania zawartości plików.
Optymalizacja⌗
Zasada numer 1 każdego CTFa brzmi: 1. Jeśli napisałeś skrypt w Pythonie i działa za wolno - użyj pypy *. Posiadam pypy w tej jedynej i prawdziwej wersji czyli 2.x. Co za tym idzie musiałem dokonać drobnej zmiany w linijce 12 czyli tam, gdzie używamy “bytes” z racji innego handlingu stringów, bajtów etc. niż w rodzinie języka 3.x. Postać zmienionej formuły wygląda następująco:
if (zlib.crc32(bytes(j)) & 0xffffffff) == fn['crc32']:
Powinno wystarczyć. Zmierzyłem wykonanie za pomocą funkcji time.time(). Wynik jest bardziej zadowalający. Zamiast 8 minut czekałem już tylko ~180 sekund czyli 3 minuty (thanx captain obvious!). Jest progres.
Kolejnym naturalnym krokiem optymalizacji zadania, będzie wykorzystanie wielu wątków. Znaczy tak by było w języku typu C++. W przypadku Pythona, a przynajmniej wzorcowej implementacji cPythona i posiadającego JIT pypy istnieje coś takiego jak GIL czyli “global interpreter lock”. To nic innego jak mutex, który dba o to, aby w danym momencie tylko jeden proces maszyny wirtualnej wykonywał instancję bajtkodu. Co to znaczy? W cPythonie, za pomocą “threads” nie wykonamy obliczeń równolegle na oddzielnych rdzeniach CPU. Szkoda, bo to jest to na czym nam zależy. Oczywiście istnieją rozwiązania pośrednie jak Jython czy IronPython, które GILa nie posiadają. Tak samo może on zostać pominięty podczas wykonywania natywnego kodu C (notabene to się dzieje podczas korzystania z bibliotek takich jak zlib czy hashlib). Ale ja nie chcę pisać w C/C++, chcę w Pythonie! <powiedział foxtrot i tupnął nogą>. Co więc nam zostaje?
Z pomocą przychodzi biblioteka multiprocessing. Już sama nazwa wskazuje, że nie mamy doczynienia z threadami tylko procesami. To rozwiązanie dedykowane do obejścia, w pewnym stopniu, obecności GILa.
Aby skorzystać z klasy Pool, musiałem trochę przemodelować wejściowy solver. Można też ręcznie podzielić pulę CRC i odpalić kilka instancji interpretera. Wolę jednak rozwiązanie automatyczne. Schedluer zna się na swojej pracy na tyle, że nie będę mu narzucał swoich konwencji.
Kod nowej wersji wygląda tak:
#!/usr/bin/env python
import zipfile
import zlib
import itertools
import string
import multiprocessing as mp
from time import time
def crack(crc32, s):
for i in itertools.product(list(string.printable), repeat=s):
j = ''.join(i)
if (zlib.crc32(bytes(j, 'utf-8')) & 0xffffffff) == crc32:
return j
return ""
def main():
z = zipfile.ZipFile('m012.zip')
fs = []
for i in z.infolist():
fs.append((i.CRC, int(i.file_size)))
pool = mp.Pool(processes=4)
k = pool.starmap(crack, fs)
print("And the flag is: {}".format(''.join(k)))
if __name__ == '__main__':
t0 = time()
main()
print("Duration: {}".format(time() - t0))
Bingo! Czas wykonania na 4 rdzeniach wynosi już tylko 140s, co daje trochę ponad 2 minuty. Mamy rekordzistę na razie. Zużycie procesora po odpaleniu tego *cough* potwora *cough*:
Minusem tego rozwiązania jest obniżona responsywność systemu. Czuć lekkie obciążenie procesami typu CPU-bound. Co się zmieniło? Starmap wywołuje funkcje crack z jej dwoma parametrami. Przy czym Pool procesów wynosi 4. Co za tym idzie 4 instancje Pythona jednocześnie (równolegle) łamią 4 różne CRC. Zgodnie z dokumentacją map jak i starmap zwrócą wartości w kolejności odpalania procesów (co nie znaczy, że w kolejności ich zakończenia). Procesy startowały według kolejności plików, gdyby tak nie było potrzebowałbym dodatkowego argumentu, indeksu informującego o kolejności przetworzonej liczby (lub musiałbym zgadywać kolejność wyjścia, co już mniej mi się podoba). Nieuszeregowane wyniki można (przy delikatnie zwiększonej wydajności) otrzymać za pomocą Pool.imap_unordered. Kolejną opcją wykonania współbieżnego jest startowanie x procesów, które przetwarzać będą to samo CRC, ale od zaczną od różnych wartości. Po złamaniu jednej sumy, wszystkie x workerów kończy działanie i wystartowane zostają następne x workery z kolejnym CRC.
Ostatnią możliwością na jaką wpadłem było “odwrócenie” wartości CRC32. Nie jest to kryptograficzna funkcja skrótu i wydaje się, że dla maksymalnie 4 bajtowych wartości powinno obyć się bez problemu. Okazuje, że da się to zrobić. Tutaj znajduje się szerokie objaśnienie problemu. Jak na zadanie CTFowe, obracanie CRC32 w tym wypadku wydaje się zbyt pracochłonne do samodzielnej implementacji. Aczkolwiek posiłkując się SAT solverami jak z3, może udałoby się dojść do szybkiego i bezbolesnego rozwiązania. Moim zdaniem jest to nieopłacalne. Pierwsze rozwiązanie zajęło mi 10 minut pisania kodu (+ wcześniejsze zapoznanie się z sytuacją i standardem) + 8 minut wykonania. W przypadku reversowania CRC trwałoby to znacznie dłużej. Jeśli kogoś interesowałby temat, to polecam lekturę i dostępne toolsy:
*Druga zasada brzmi:
2. Jeśli pypy nie daje rady nawet z multiprocessingiem to przepisz do do C++, zoptymalizuj co się da, dodaj openmp i odpal to na wypasionym AWS
* Podziękowania dla użytkownika @marbel82 za korektę linku!